图灵奖得主杨立昆、菲尔兹奖得主Freedman同时加盟,全球首家能量模型商业化公司诞生
去年底刚从 Meta 离职的图灵奖得主杨立昆(Yann Lecun),在他宣布创办自己的世界模型公司 AMI Labs 后还不到两个月,就以另一重身份出现在公众视野里。本周三,硅谷初创公司 Logical Intelligence 宣布杨立昆出任其技术研究委员会主席。与此同时,这家成立仅六个月的公司发布了名为 Kona 1.0 的旗舰产品,据称是首个正式进入商业化的能量推理模型(Energy-Based Reasoning Model,EBRM)。

关于大语言模型能否实现 AGI,业界的质疑从未停止。如果答案是否定的,替代方案在哪里?Logical Intelligence 给出的答案是:能量模型(EBM)。在该公司创始人 Eve Bodnia 看来,LLM 本质上是一场猜词游戏。你给它一个提示,它就预测下一个词出现的概率,循环往复,直到生成一段貌似通顺的回答。问题在于,“貌似通顺”和逻“辑正确”之间隔着一道深渊。
Bodnia 在接受《金融时报》采访时打了个比方:你教会一只猫像狗一样叫,它也不会因此变成一只狗。LLM 能写出像模像样的数学证明或代码,但它并不真正理解这些符号背后的推理链条。一旦任务复杂度提升,或者约束条件增多,它就开始犯错,而且往往错得毫无章法。
杨立昆也反复表达过类似的观点。事实上,他在过去几年反复强调,仅靠扩展 LLM 的规模不可能实现真正的人类水平智能。他在此前的播客中直言,那些认为只需要不断做大模型就能通向超级智能的想法是“扯淡”(原话是 bullshit)。
杨立昆的核心论点是:LLM 缺乏对物理世界的真实理解,它们只是在文本空间里做模式匹配,无法像人类或动物那样通过与环境互动来学习因果关系。他甚至说过,一只家猫拥有的常识都比 GPT-4 多。
于是,当杨立昆的名字出现在 Logical Intelligence 的公告里时,毫无疑问这也是他用行动为 EBM 模型站台。杨立昆本人也在声明中说,他一直认为真正的推理应该被表述为优化问题,这正是能量模型的基础,即通过最小化一个能量函数来完成推理和推断。他评价 Logical Intelligence 是“第一家将基于 EBM 的推理从研究概念推向产品的公司”。
那么,EBM 的具体工作原理是什么?为什么它被认为可能弥补 LLM 的短板?
简单来说,EBM 会为每个候选状态分配一个“能量”分数。能量越低,意味着这个状态越符合约束条件和目标;能量越高,说明有什么地方出了问题。而这种评分机制可以施加在部分完成的推理链条上,而不必等到最终答案出来才知道对错。这就像下棋时能评估每一步棋的优劣,而不是非要等到终局才知道输赢。
Logical Intelligence 声称,他们的模型 Kona 在三个层面解决了 LLM 推理的固有缺陷。第一,Kona 是非自回归的。LLM 逐词生成文本,要想修正前面的错误,往往需要重新生成一大段前缀,效率很低。Kona 则可以同时生成完整的推理轨迹,并根据约束直接进行优化。
第二,Kona 使用全局评分而非局部评分。LLM 的预训练目标是预测下一个词,与长链条推理的整体正确性无关。Kona 学到的能量函数可以端到端地评估推理轨迹的质量。
第三,Kona 在连续潜在空间中推理。LLM 的输出是离散的 token 序列,很难通过梯度信息做细粒度的局部修正。Kona 输出的是稠密向量,可以利用近似梯度进行可控的编辑,逐步提升推理的一致性。
Logical Intelligence 同时发布了名为 Aleph 的智能体编排层,专门用于协调 Kona、LLM 和其他工具的调用。该公司将 Aleph 与 OpenAI 的 GPT-5.2 配对,在 PutnamBench 上取得了 99.4% 的正确率。
PutnamBench 是一个以 Putnam 数学竞赛题目为基础的形式化推理基准,包含来自该竞赛过去 50 多年的 672 道难题,每道题都需要用 Lean 等证明语言写出形式化证明,并由外部编译器验证正确性。
根据公开的排行榜信息,这一成绩把 Logical Intelligence 推到了该基准的榜首位置。据公司披露,在此次评测中,Aleph 还自动发现了 15 道题目的形式化描述存在错误,并提出了修正建议,这些修正均得到 PutnamBench 团队的核实确认。
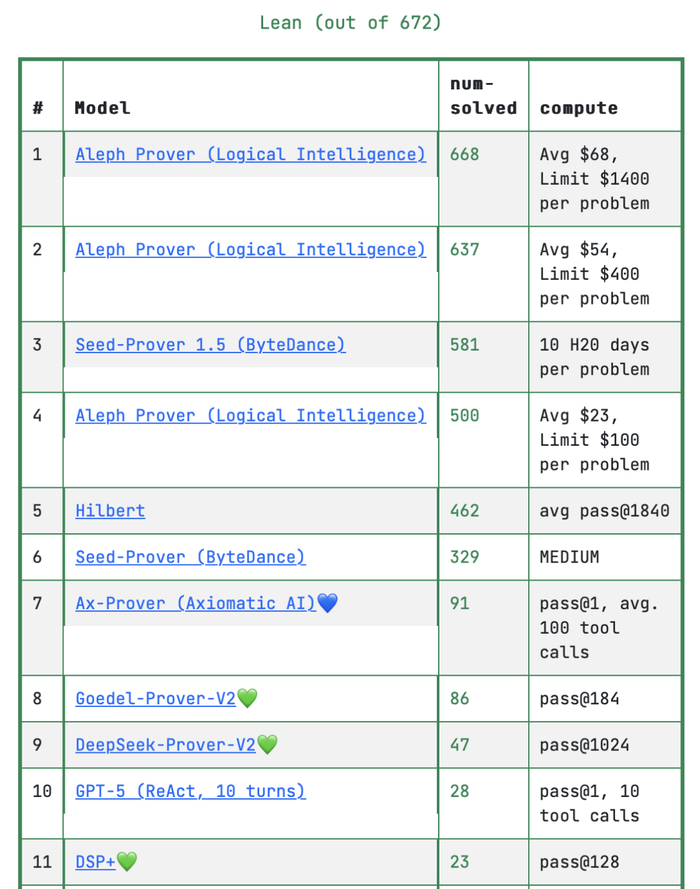
图丨Putnam Bench 测试结果(来源:PutnamBench)
不过要强调的是,Aleph 本身是基于 LLM 的(它用的是 GPT-5.2),其亮点在于编排和协调能力,而不是完全抛开 LLM 另起炉灶。按照 Bodnia 的说法,Aleph 是一个“内部工具”,用于测试公司正在构建的数学环境的严谨性;真正代表公司技术核心的是 Kona 这个 EBRM。她在去年 12 月的一次采访中直言:Aleph 的表现证明了我们的基础是坚实的,但它只是我们核心模型能力的一个零头。
Kona 1.0 于 2026 年 1 月 21 日正式公开演示,第一个展示的能力是解数独。在公司网站的实时对比中,Kona 与 OpenAI、Google、Anthropic 等公司的领先 LLM 正面对决,Kona 在速度和能耗上都展现出明显优势。公司表示后续还会加入国际象棋和围棋的演示,目标是让公众直观理解“基于能量的推理”与“基于概率的猜测”之间的区别。
在一篇题为《认知的艺术》的博客文章中,Bodnia 写道,LLM 让很多人感到兴奋,因为它们很擅长回答个人问题,互动起来很自然,很容易让人幻想它们能处理更难的问题。
但仔细想想,我们每天面对的任务大多数并不是纯粹的语言问题,有的需要空间推理,有的依赖逻辑、规划或情绪感知,还有很多根本无法用语言完全表达。智能不是静态的,而是适应性的。LLM 在某些事情上做得很好,但它们只是一种智能,许多问题需要另一种路径。
而这种观点也与 Eve Bodnia 的独特背景不无关系,她出生于哈萨克斯坦,18 岁移民美国,先在社区大学就读,后转入加州大学伯克利分校,又在加州大学圣芭芭拉分校攻读博士。她的研究方向包括暗物质探测、量子力学和粒子物理,发表过 22 篇相关论文,还与 Google Quantum AI 有过合作。
她个人网站上的自我介绍显示,她对代数拓扑和李群在学习系统形式化中的应用很感兴趣。这种数学物理背景使她对可验证性有一种近乎执念式的追求。
除了 Bodnia 和杨立昆,Logical Intelligence 还拉来菲尔兹奖得主 Michael Freedman 出任首席数学官,前 Facebook 工程师、国际大学生程序设计竞赛(ICPC)世界冠军 Vlad Isenbaev 担任首席 AI 官,曾任币安首席战略官和通用电气高管的 Patrick Hillmann 则负责战略规划。

图丨Logical Intelligence 创始团队(来源:Logical Intelligence)
根据《金融时报》等媒体报道,Logical Intelligence 正在筹备新一轮融资,目标估值在 10 亿至 20 亿美元之间。公司计划在本季度晚些时候与能源、先进制造和半导体行业的部分合作伙伴启动 Kona 1.0 的试点项目。
当然,这个领域并非只有 Logical Intelligence 一家在探索。Robinhood 联合创始人 Vlad Tenev 投资的 Harmonic 同样专注于形式化推理,其旗舰模型 Aristotle 在 2025 年国际数学奥林匹克竞赛中达到金牌水平。
不过,Harmonic 走的是数学超级智能(Mathematical Superintelligence)路线,仍在 LLM 框架内通过形式化验证来消除幻觉;而 Logical Intelligence 则明确标榜自己是“语言无关的”(language-free),直接绕过 token,在结构化状态空间中推理。两者的技术路径存在本质差异。
杨立昆本人的布局更是多线并行。他创办的 AMI Labs 专注于世界模型,据报道正以约 35 亿美元的估值融资 5 亿欧元,总部将设在巴黎。世界模型的目标是让 AI 理解物理世界的因果关系,通过视频和空间数据学习,而不只是消化文本。
据报道,杨立昆和 Bodnia 都认为真正的人类水平 AI 需要组合多种模型。从杨立昆同时参与世界模型公司 AMI Labs 和能量型推理公司 Logical Intelligence 来看,他显然也是在多个技术方向同时下注。
也有人持怀疑态度。一位匿名 AI 投资人在接受 Upstarts 采访时表示,他怀疑大多数 AI 生成的代码最终是否真的需要形式化验证。毕竟,形式化方法在狭义的、高度规范化的领域效果最好,能否推广到更广泛的应用场景仍是未知数。
更何况,OpenAI、Google 等大型实验室也在大力改进自家推理模型的可靠性。Harmonic 的 CEO Tudor Achim 承认,形式化证明系统在精确度上无可挑剔,但要转化为可持续的商业收入,还需要证明自己在学术竞赛之外的实际价值。
参考资料:
1.https://www.ft.com/content/157bb0e3-9d6c-47ac-afc5-6944981e10ef
2.https://www.upstartsmedia.com/p/math-ai-startups-push-new-models
3.https://finance.yahoo.com/news/logical-intelligence-achieves-76-percent-141500227.html
4.https://logicalintelligence.com/blog/energy-based-models-for-reasoning
运营/排版:何晨龙
网友评论 (128)